Chapter 3 The whole game
Figure 3.1: Screenshot of the first level of Megaman X (Capcom, 1993)
3.1 Analysing Trump’s tweets
We are going to use an example to illustrate the whole process of a typical automated content analysis scenario. This is called the “Play the Whole Game” approach by Perkins (2010).1 In this example, we start with a simple research question or hypothesis. Let’s say I want to reproduce a very famous analysis of Donald Trump’s tweets. This example is very well-known in the data science world, probably because David Robinsom (one of the authors of the tidytext package) used this example to demonstrate the power of his package (and made him on the television). In David Robinson’s TV-worthy conclusion, he found that tweets from an Android phone (probably from Trump himshelf) are more negative than tweets from an iPhone (probably from his campaign). We can refomulate this into a research question: are tweets from Donald Trump’s twitter account tweeted using an iPhone more positive than those tweeted using an Android phone?
There are many elements to unpack from the above paragraph, but the above paragraph illustrates how data scientists and automated content analysis practitioners approach the problem differently. The utmost important element is: All automated content analysis project must have hypotheses to test or research questions to answer. If a project without hypotheses or research questions, it can hardly be called automated content analysis (see Chapter 2 for longer discussion). We also need to specify the context we are interested in analyzing (Donald Trump and his Twitter). Later on, we need to think about the operationalization of variables (what is positive?), data collection plan and data analysis strategy.
In this book, however, we are not going to focus on:
- how to form hypotheses or research questions
- how to collect your (text) data.
The reason for excluding the former is simple: It needs to be supported by communication theories. As a book that is intented as an research methods book, it is probably a bit too much to ask.2 For the latter, the exclusion of it is due to the fact that there are good papers and textbooks available. The book chapter by Liang and Zhu (2017) is probably a good start. Munzert et al. (2014) ’s Automated Data Collection with R is an in-depth manual.
At this point, you should probably go to preregister the hypotheses of this automated content analysis project. And then you should study rtweet and academictwitteR. However, even you know how to use these packages and have access to the Twitter API, the data is not accessible anymore. Following the 2021 Capitol attack, his account has been permanently suspended.
Let’s suppose the data is now magically available. In the companion website of this book, you can find the data file with tweets from Donald Trump’s tweet account before he assumes duty as the president of the United States (2015-Jan to 2016-Dec). We need to select this time range because Donald Trump’s account did not tweet anymore using an Android phone after March, 2017.
The data looks like this:
trump_tweets <- import('./data/trump.json') %>% as_tibble %>% mutate(created_at = parse_date_time(created_at, orders = '%a %b %d %H:%M:%S %z %Y')) %>% filter(created_at >= ymd_hms('2015-01-01 00:00:00') & created_at <= ymd_hms('2016-12-31 23:59:59'))
trump_tweets## # A tibble: 11,761 × 7
## source text created_at retweet_count favorite_count is_retweet
## <chr> <chr> <dttm> <int> <int> <lgl>
## 1 Twitte… "RT @rea… 2016-12-31 18:59:04 9529 0 TRUE
## 2 Twitte… "Happy B… 2016-12-31 18:58:12 9529 55601 FALSE
## 3 Twitte… "Happy N… 2016-12-31 13:17:21 141853 350860 FALSE
## 4 Twitte… "Russian… 2016-12-30 22:18:18 23213 84254 FALSE
## 5 Twitte… "Join @A… 2016-12-30 19:46:55 7366 25336 FALSE
## 6 Twitte… "Great m… 2016-12-30 19:41:33 34415 97669 FALSE
## 7 Twitte… "My Admi… 2016-12-29 14:54:21 11330 45609 FALSE
## 8 Twitte… "'Econom… 2016-12-28 22:06:28 13919 51857 FALSE
## 9 Twitte… "not any… 2016-12-28 14:25:11 34542 117710 FALSE
## 10 Twitte… "We cann… 2016-12-28 14:19:46 30237 106626 FALSE
## # … with 11,751 more rows, and 1 more variable: id_str <chr>Up to this point, you might notice this book uses tidyverse—or more precisely, dplyr—for data manipulation. Yes. If you are not familar with dplyr, it is a good idea for you to read the book R4DS (available online). The book you are reading now is not an introduction to dplyr. But as a refresher, let me show you all the dplyr you will need to deal with 80% of the situations. You probably only need to know 5 verbs and then combine them together. You may call these 6 verbs “Big Six” if you like.
3.2 An express summary of tidyverse
The first verb is select. It is used to select particular column(s) from a data frame. By the way, our data is a tibble, an arguably nicer version of data frame. Suppose we want to select only the columns source and text.
## # A tibble: 11,761 × 2
## source text
## <chr> <chr>
## 1 Twitter for iPhone "RT @realDonaldTrump: Happy Birthday @DonaldJTrumpJr!\nh…
## 2 Twitter for iPhone "Happy Birthday @DonaldJTrumpJr!\nhttps://t.co/uRxyCD3hB…
## 3 Twitter for Android "Happy New Year to all, including to my many enemies and…
## 4 Twitter for Android "Russians are playing @CNN and @NBCNews for such fools -…
## 5 Twitter for iPhone "Join @AmerIcan32, founded by Hall of Fame legend @JimBr…
## 6 Twitter for Android "Great move on delay (by V. Putin) - I always knew he wa…
## 7 Twitter for iPhone "My Administration will follow two simple rules: https:/…
## 8 Twitter for iPhone "'Economists say Trump delivered hope' https://t.co/SjGB…
## 9 Twitter for Android "not anymore. The beginning of the end was the horrible …
## 10 Twitter for Android "We cannot continue to let Israel be treated with such t…
## # … with 11,751 more rowsThe second verb is filter. It is used to filter rows from a tibble based on certain criteria. Suppose you want to get all the rows which were tweeted from an Android phone.
## # A tibble: 7,015 × 2
## source text
## <chr> <chr>
## 1 Twitter for Android Happy New Year to all, including to my many enemies and …
## 2 Twitter for Android Russians are playing @CNN and @NBCNews for such fools - …
## 3 Twitter for Android Great move on delay (by V. Putin) - I always knew he was…
## 4 Twitter for Android not anymore. The beginning of the end was the horrible I…
## 5 Twitter for Android We cannot continue to let Israel be treated with such to…
## 6 Twitter for Android Doing my best to disregard the many inflammatory Preside…
## 7 Twitter for Android The U.S. Consumer Confidence Index for December surged n…
## 8 Twitter for Android President Obama campaigned hard (and personally) in the …
## 9 Twitter for Android The DJT Foundation, unlike most foundations, never paid …
## 10 Twitter for Android I gave millions of dollars to DJT Foundation, raised or …
## # … with 7,005 more rowsIn the above example, we combine two verbs (filter and select) using the pipe (%>%) operator. Some might disagree, but this method is more elegant. If you can tell a story using your dplyr code, it is probably a good code. For example, you can tell a story using the above code as such: We have our trump_tweets data, and then we filter all tweets where source contains “Android”, and then we select only the source and text columns.
So, the pipe operators in the above code are corresponding to all “and then” in the story.
From the above story, you might notice that the source column is recording from which device the tweet was tweeted, e.g. Android.
It is a good idea to see what are the other variants of “source” in our data. The next verb that we need to know is group_by.
## # A tibble: 11,761 × 7
## # Groups: source [15]
## source text created_at retweet_count favorite_count is_retweet
## <chr> <chr> <dttm> <int> <int> <lgl>
## 1 Twitte… "RT @rea… 2016-12-31 18:59:04 9529 0 TRUE
## 2 Twitte… "Happy B… 2016-12-31 18:58:12 9529 55601 FALSE
## 3 Twitte… "Happy N… 2016-12-31 13:17:21 141853 350860 FALSE
## 4 Twitte… "Russian… 2016-12-30 22:18:18 23213 84254 FALSE
## 5 Twitte… "Join @A… 2016-12-30 19:46:55 7366 25336 FALSE
## 6 Twitte… "Great m… 2016-12-30 19:41:33 34415 97669 FALSE
## 7 Twitte… "My Admi… 2016-12-29 14:54:21 11330 45609 FALSE
## 8 Twitte… "'Econom… 2016-12-28 22:06:28 13919 51857 FALSE
## 9 Twitte… "not any… 2016-12-28 14:25:11 34542 117710 FALSE
## 10 Twitte… "We cann… 2016-12-28 14:19:46 30237 106626 FALSE
## # … with 11,751 more rows, and 1 more variable: id_str <chr>It seems that we have done nothing here. But you might notice the output says “Groups: source [16]”. group_by works the best when it is combined with summarise. dplyr is smart enough to accept both British and American spellings. So you can use summarize if you want.3 We use summarise to generate one-element summary of your data. For example, you want to get the total number of rows of this data.
## # A tibble: 1 × 1
## ntweets
## <int>
## 1 11761Using the above code, we can tell a story as such: We have our trump_tweets data, and then we want to summarise our data as ntweets whereas ntweets equals to n(), i.e. number of rows. Let’s try to use this verb with group_by:
## # A tibble: 15 × 2
## source ntweets
## <chr> <int>
## 1 Facebook 2
## 2 Instagram 70
## 3 Media Studio 1
## 4 Mobile Web (M5) 2
## 5 Neatly For BlackBerry 10 5
## 6 Periscope 7
## 7 TweetDeck 2
## 8 Twitter Ads 64
## 9 Twitter for Android 7015
## 10 Twitter for BlackBerry 94
## 11 Twitter for iPad 22
## 12 Twitter for iPhone 2369
## 13 Twitter Mirror for iPad 1
## 14 Twitter QandA 10
## 15 Twitter Web Client 2097The story of the above code is: We have our trump_tweets … probably I can skip this part now, and then we group our data by source and then we summarise our data as ntweets whereas ntweets equals to n(), i.e. number of rows. So, what group_by does, is to split the data into groups by a certain column (or columns). The subsequent steps are then became group-based analysis. This principle is called “Split-Apply-Combine strategy” by Wickham (2011).
this group-based analysis shows that there are many variants! In this analysis, we keep only those tweets from iPhone and Android only. So, which verb we should use? I give you 10 seconds to think.
Well…
## # A tibble: 9,384 × 7
## source text created_at retweet_count favorite_count is_retweet
## <chr> <chr> <dttm> <int> <int> <lgl>
## 1 Twitte… "RT @rea… 2016-12-31 18:59:04 9529 0 TRUE
## 2 Twitte… "Happy B… 2016-12-31 18:58:12 9529 55601 FALSE
## 3 Twitte… "Happy N… 2016-12-31 13:17:21 141853 350860 FALSE
## 4 Twitte… "Russian… 2016-12-30 22:18:18 23213 84254 FALSE
## 5 Twitte… "Join @A… 2016-12-30 19:46:55 7366 25336 FALSE
## 6 Twitte… "Great m… 2016-12-30 19:41:33 34415 97669 FALSE
## 7 Twitte… "My Admi… 2016-12-29 14:54:21 11330 45609 FALSE
## 8 Twitte… "'Econom… 2016-12-28 22:06:28 13919 51857 FALSE
## 9 Twitte… "not any… 2016-12-28 14:25:11 34542 117710 FALSE
## 10 Twitte… "We cann… 2016-12-28 14:19:46 30237 106626 FALSE
## # … with 9,374 more rows, and 1 more variable: id_str <chr>mutate is for creating new columns.
## # A tibble: 9,384 × 2
## android text
## <lgl> <chr>
## 1 FALSE "RT @realDonaldTrump: Happy Birthday @DonaldJTrumpJr!\nhttps://t.co/…
## 2 FALSE "Happy Birthday @DonaldJTrumpJr!\nhttps://t.co/uRxyCD3hBz"
## 3 TRUE "Happy New Year to all, including to my many enemies and those who h…
## 4 TRUE "Russians are playing @CNN and @NBCNews for such fools - funny to wa…
## 5 FALSE "Join @AmerIcan32, founded by Hall of Fame legend @JimBrownNFL32 on …
## 6 TRUE "Great move on delay (by V. Putin) - I always knew he was very smart…
## 7 FALSE "My Administration will follow two simple rules: https://t.co/ZWk0j4…
## 8 FALSE "'Economists say Trump delivered hope' https://t.co/SjGBgglIuQ"
## 9 TRUE "not anymore. The beginning of the end was the horrible Iran deal, a…
## 10 TRUE "We cannot continue to let Israel be treated with such total disdain…
## # … with 9,374 more rowsLast but not least, arrange is for sorting.
## # A tibble: 9,384 × 2
## android text
## <lgl> <chr>
## 1 FALSE "RT @realDonaldTrump: Happy Birthday @DonaldJTrumpJr!\nhttps://t.co/…
## 2 FALSE "Happy Birthday @DonaldJTrumpJr!\nhttps://t.co/uRxyCD3hBz"
## 3 FALSE "Join @AmerIcan32, founded by Hall of Fame legend @JimBrownNFL32 on …
## 4 FALSE "My Administration will follow two simple rules: https://t.co/ZWk0j4…
## 5 FALSE "'Economists say Trump delivered hope' https://t.co/SjGBgglIuQ"
## 6 FALSE "The world was gloomy before I won - there was no hope. Now the mark…
## 7 FALSE "#MerryChristmas https://t.co/5GgDmJrGMS"
## 8 FALSE "Happy #Hanukkah https://t.co/UvZwtykV1E"
## 9 FALSE "As to the U.N., things will be different after Jan. 20th."
## 10 FALSE "The resolution being considered at the United Nations Security Coun…
## # … with 9,374 more rowsIt seems that it did nothing. We can set it to arrange by descending order. So that the tweets from Android are on top.
## # A tibble: 9,384 × 2
## android text
## <lgl> <chr>
## 1 TRUE Happy New Year to all, including to my many enemies and those who ha…
## 2 TRUE Russians are playing @CNN and @NBCNews for such fools - funny to wat…
## 3 TRUE Great move on delay (by V. Putin) - I always knew he was very smart!
## 4 TRUE not anymore. The beginning of the end was the horrible Iran deal, an…
## 5 TRUE We cannot continue to let Israel be treated with such total disdain …
## 6 TRUE Doing my best to disregard the many inflammatory President O stateme…
## 7 TRUE The U.S. Consumer Confidence Index for December surged nearly four p…
## 8 TRUE President Obama campaigned hard (and personally) in the very importa…
## 9 TRUE The DJT Foundation, unlike most foundations, never paid fees, rent, …
## 10 TRUE I gave millions of dollars to DJT Foundation, raised or recieved mil…
## # … with 9,374 more rowsOh, yea! We have our data! So we should do our sentiment analysis now, right?
NO! Nein! Non! いいえ! 唔係!
3.3 Creating ground truth data
This is another split-path between data scientists and automated content analysts.
If you know nothing about automated content analysis, the traditional way of dealing with our data is to manually code all tweets. The word “code” as a verb can create confusion here, because it can also mean “programming.”4 In this programming-heavy book, I am going to use another verb for “code” (in the social sciences’ sense): annotate. I believe this term can still capture most, but not all, nuances of the verb “code” (in the social sciences’ sense). For “coding” in programmers’ sense, I am going to use “programming”.
Sorry for the detour. Traditionally, social scientists approach this problem by annotating the unstructured data into a form suitable for computer analysis. A tweet is a bunch of characters that a (naive) computer cannot extract meanings—or semantics—out of it. However, whether or not a tweet is positive is a semantic problem. Homo sapiens have a brain and some of us have the knowledge in English to determine the semantics of a piece of English text. We need to tell the computer, what semantically is expressed in a tweet. This procedure is called annotation.
In an academic setting, it usually means the principal investigator of this project (i.e. you) would assemble a team of student assistants to annotate all tweets by reading them one by one and then asserting every one of them if they are positive or not. In order to ensure interrater reliability, we usually assign at least two student assistants to annotate the same set of tweets.
This procedure of annotation is notoriously expensive. In Germany, for instance, one needs to pay a student assistant €15.8 per hour in 2020. Let’s assume a student assistant can annotate 4 tweets per minute. In order to read every single tweets (n = 15,267) by two students, it takes (15,267 x 2) / 4 = 7,633.5 man-minutes or 127.2 man-hours. Therefore, the principal investigator (i.e you) needs to pay €2009.76 just for the annotation. It is not a handsome amount of money: You can buy 4464 packs of instant ramen that you can eat for about a year. But remember, now you are not doing this for your PhD thesis. It is just an exercise of a stupid book. If you are willing to pay this, great for you. If you are not willing to pay this, what should you do?
Instead of asking your student assistants to annotate all data, we can use a computer to do that. But as I said previously, a (naive) computer cannot extract semantics from a piece of text. However, it can extract an approximated version of semantics —or a surrogate measure— from text content. So, what is a surrogate? The dictionary by Upton and Cook (2014) gives this definition: “A variable that can be measured (or is easy to measure) that is used in place of one that cannot be measured (or is difficult to measure)”. A very similar term is “proxy measure” but there is one crucial difference: Proxy measure is a variable that is used in place of one that cannot be measure. Period. There is no “or” after it. As indicated previously, we can measure the negativity or a tweet by manual data categorization, it is just “diffuclt to measure” due to the cost. Thus, we use a surrogate measure instead.
A good surrogate measure should have a strong correlation with the original variable. For example, it is difficult to assess the wealth of a family. It is just difficult, not impossible. As a surrogate measure, we can use the value of the family’s house as an approximation. We know that in normal circumstances, the two variables (the wealth of the family and the value of the family’s house) should be correlated. But for this correlation to be valid, there are many assumptions: people can actually afford a house, rich people buy expensive houses and the housing market is not regulated, just to name three. A surrogate measure is good only when the domain of the measurement can hold the assumptions that maintain the correlation between the surrogate measure and the actual measure. We will come back to this point in Chapter 4.
We —as a practitioner of automated content analysis— cannot blindly accept a surrogate measure is always good. It is related to the fact that we are doing automated content analysis and automated content analysis is actually still a content analysis. In the next chapter, we will come back to the validity requirement of any content analysis, automated or not.
Up to this point, we have a dilemma: Manual annotation is too expensive but automated content analysis is just a surrogate measure. What should we do?
A simple solution is to test whether the domain of our measurement fits the original assumptions. Therefore, we need to test the correlation between the approximated semantics extracted by the computer and the semantics extracted by humans. As said before, a good surrogate measure should have a strong correlation with the original measurement. For this, we do not need to manually categorize a lot of tweets. A represenative subset of tweets will do. We have a name for these manually annotated data for testing the validity of a tool: ground truth data.
We will talk more on how to create ground truth data in Chapter 4. As an excercise of creating ground truth data, let’s say we want to create a set of ground truth data with a random sample of 30 tweets. It can be done easily with:
set.seed(42)
trump_tweets %>% sample_n(30) %>% select(text) %>% rio::export('data/trump_tweet30.rds')And then, I ask my team of two student assistants to manually categorize these 30 tweets. This task should take (30 x 2) / 4 = 15 man-minutes. The cost of it (€3.95) is only a few packs of instant ramen. Or, if you are middle class and don’t mind damaging the environment, it is the cost of a “coffee to go”.
The annotation procedure is simple, or even simplified. We will talk about the setup of such annotation task using the R package oolong (Chan and Sältzer 2020) in Chapter 5.
The two student assistants annotate the 30 tweets based on the level of positive sentiment with a 5-point Likert (visual analog) scale, i.e.
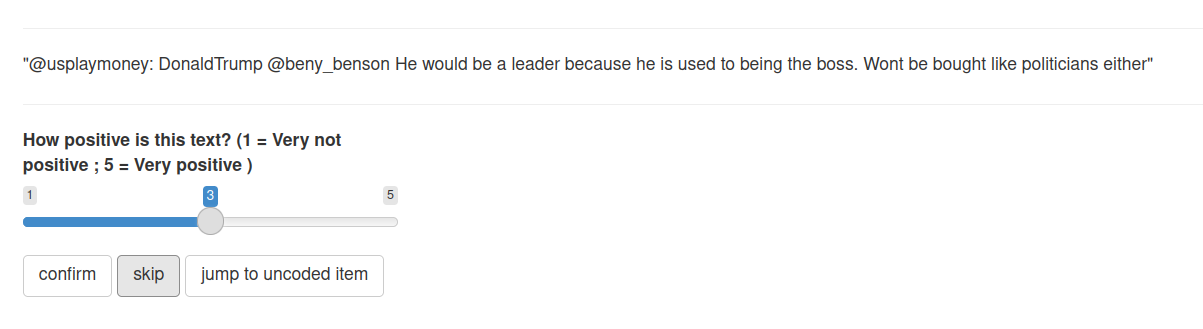
Figure 3.2: Annotating the sentiment of a random tweet from Trump
And the data looks like this:
## # A tibble: 30 × 3
## text rater1 rater2
## <chr> <int> <int>
## 1 "\"@RealityTVBliss: If I was ever on #CelebrityApprentice, the… 3 3
## 2 "Wow, I have had so many calls from high ranking people laughi… 2 2
## 3 "\"@pjs307: @WalshFreedom Will be highest rated show ever, @re… 4 4
## 4 "\"@BizMotivationTV: Go to work, be smart, think positively an… 4 4
## 5 "\"@Jimbos2002: @Morning_Joe Video: Hillary referring to blac… 2 2
## 6 "\"@DavidNYCT: @realDonaldTrump We will!\"" 3 3
## 7 "\"@OscarBagPledge: Congrats @LeezaGibbons @ApprenticeNBC @rea… 3 4
## 8 "Thank you Maine, New Hampshire and Iowa. The waiting is OVER!… 4 4
## 9 "Via @trscoop: “Mark Levin DEFENDS Trump: Hillary Clinton is a… 1 1
## 10 "National Review is a failing publication that has lost it's w… 1 2
## # … with 20 more rowsWe consider the two columns of coder1 and coder2 our ground truth data. In the next section, we will use these ground truth data to validate the automatically extracted semantics from Trump’s tweets.
3.4 Automated sentiment analysis: AFINN
Now, with the ground truth data, we can finally do the so called ‘sentiment analysis’. Before, we really do it, I would like to remind you for one last time that the semantics extracted by these method are an approximated version of the true semantics. Thus, it is a surrogate at best.
The simpliest method for doing a sentiment analysis is using a dictionary-based method. These methods will be explained in Chapter 6. In short, these methods rely on three simple assumptions to calculate the overall sentiment of a piece of text. A dictionary is a collection of words. For example, a negative dictionary might have words that contain negative meanings, for example, f-words. A positive dictionary might have words such as good, nice, wonderful. A piece of text with a lot of words in the negative dictionary should have a higher negativity and vice versa.
There are many of these dictionaries available. These readily available dictionaries are called off-the-shelf dictionaries. In Chapter 6, we will discuss the problems of using them. But one way to avoid those problems is to first create ground truth data and validate these dictionaries before use. Here, we are going to use the AFINN dictionary (Nielsen 2011). It is a dictionary designed for measuring sentiment of microblog data, e.g. tweets.
## Dictionary object with 11 key entries.
## - [neg5]:
## - bastard, bastards, bitch, bitches, cock, cocksucker, cocksuckers, cunt, motherfucker, motherfucking, niggas, nigger, prick, slut, son-of-a-bitch, twat
## - [neg4]:
## - ass, assfucking, asshole, bullshit, catastrophic, damn, damned, damnit, dick, dickhead, fraud, frauds, fraudster, fraudsters, fraudulence, fraudulent, fuck, fucked, fucker, fuckers [ ... and 23 more ]
## - [neg3]:
## - abhor, abhorred, abhorrent, abhors, abuse, abused, abuses, abusive, acrimonious, agonise, agonised, agonises, agonising, agonize, agonized, agonizes, agonizing, anger, angers, angry [ ... and 244 more ]
## - [neg2]:
## - abandon, abandoned, abandons, abducted, abduction, abductions, accident, accidental, accidentally, accidents, accusation, accusations, accuse, accused, accuses, accusing, ache, aching, admonish, admonished [ ... and 945 more ]
## - [neg1]:
## - absentee, absentees, admit, admits, admitted, affected, afflicted, affronted, alas, alert, ambivalent, anti, apologise, apologised, apologises, apologising, apologize, apologized, apologizes, apologizing [ ... and 289 more ]
## - [zero]:
## - some kind
## [ reached max_nkey ... 5 more keys ]Sorry for the strong language. AFINN contains categories of words sorted by valence values from -5 (neg5) to +5 (pos5). For example, the word ‘bastard’ is -5 in terms of valence value.
According to original paper of AFINN (Nielsen 2011), the AFINN sentiment score of a tweet is calculated as the total valence values of matching words divided by the total number of words. For example, the AFINN sentiment score of the tweet “He is a bastard” is -5 / 4 = 1.25. The total valence values of matching words is 5 because there is only one matching word (bastard) and its valence value is -5. In total, this tweet has 4 words.
The following program calculates the correponding AFINN score of each tweet using the R package quanteda (Benoit et al. 2018). In short, this program creates a document-feature matrix (DFM) using Trump’s tweets and then look up this DFM by the AFINN dictionary to seek for matching words. And then, we convert this DFM into a data frame and then do our dplyr magic to calculate the AFINN sentiment score. It might look a bit scary and don’t worry, we will walk through this program again step-by-step in Chapter 6.
## Warning: 'dfm.character()' is deprecated. Use 'tokens()' first.## Warning: '...' should not be used for tokens() arguments; use 'tokens()' first.## text1 text2 text3 text4 text5 text6
## 0.05000000 0.12000000 0.11111111 0.58333333 0.16666667 0.00000000
## text7 text8 text9 text10 text11 text12
## 0.16666667 0.09090909 -0.19047619 -0.26923077 0.00000000 -0.13333333
## text13 text14 text15 text16 text17 text18
## 0.00000000 0.00000000 -0.13636364 0.00000000 0.47619048 0.22222222
## text19 text20 text21 text22 text23 text24
## 0.14285714 0.77777778 0.00000000 -0.04761905 -0.06666667 0.53333333
## text25 text26 text27 text28 text29 text30
## 0.16666667 0.00000000 0.00000000 0.69230769 0.18750000 0.25000000Once again, this AFINN sentiment score is a surrogate measure of semantics. We can test the correlation between the AFINN score and the results from two human coders.
##
## Pearson's product-moment correlation
##
## data: trump_tweet30_coded$rater1 and afinn_score
## t = 3.6976, df = 28, p-value = 0.0009395
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.2677772 0.7734500
## sample estimates:
## cor
## 0.5727884##
## Pearson's product-moment correlation
##
## data: trump_tweet30_coded$rater2 and afinn_score
## t = 2.669, df = 28, p-value = 0.01251
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.1075218 0.6974559
## sample estimates:
## cor
## 0.450346The two correlation coefficients are statistically sigificant. The scatterplot of the two measures is like so:
## `geom_smooth()` using formula 'y ~ x'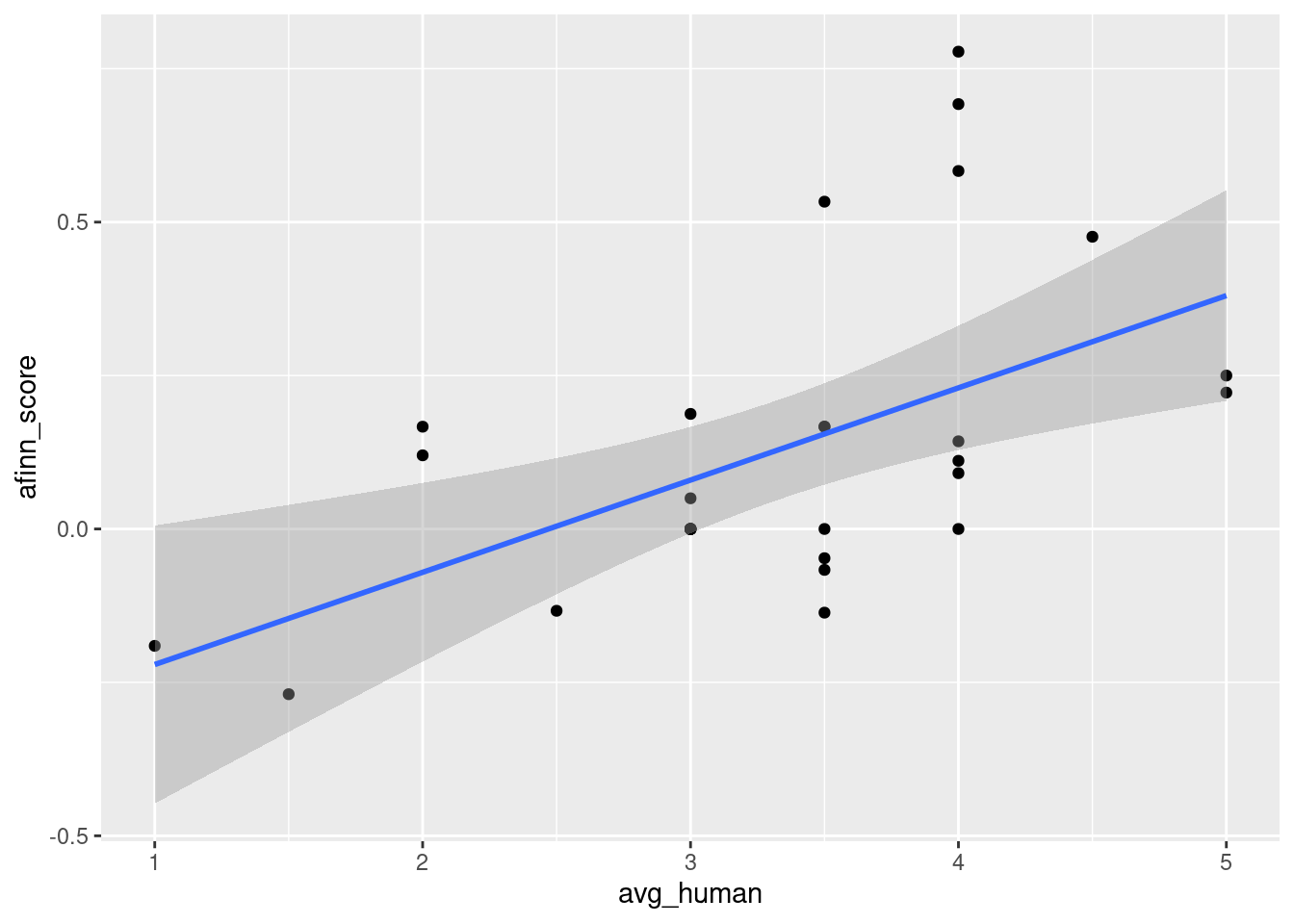
(#fig:corafinn_human)Scatterplot of the correlation between human categorization and AFINN score.
It seems that we have evidence to show the AFINN score is a good surrogate measure of sentiment because it has a good correlation with human judgements. Only after this step, we can apply the method to all of the tweets.
3.5 Comparing tweets from Android and iPhone
So, we have shown in the previous sections that AFINN score is a good surrogate measure of sentiment. Now, we can calculate the AFINN score of all tweets.
trump_tweets %>% filter(str_detect(source, "Android|iPhone")) %>% mutate(android = str_detect(source, "Android")) %>% select(android, text) -> trump_tweets_target
trump_tweets_target## # A tibble: 9,384 × 2
## android text
## <lgl> <chr>
## 1 FALSE "RT @realDonaldTrump: Happy Birthday @DonaldJTrumpJr!\nhttps://t.co/…
## 2 FALSE "Happy Birthday @DonaldJTrumpJr!\nhttps://t.co/uRxyCD3hBz"
## 3 TRUE "Happy New Year to all, including to my many enemies and those who h…
## 4 TRUE "Russians are playing @CNN and @NBCNews for such fools - funny to wa…
## 5 FALSE "Join @AmerIcan32, founded by Hall of Fame legend @JimBrownNFL32 on …
## 6 TRUE "Great move on delay (by V. Putin) - I always knew he was very smart…
## 7 FALSE "My Administration will follow two simple rules: https://t.co/ZWk0j4…
## 8 FALSE "'Economists say Trump delivered hope' https://t.co/SjGBgglIuQ"
## 9 TRUE "not anymore. The beginning of the end was the horrible Iran deal, a…
## 10 TRUE "We cannot continue to let Israel be treated with such total disdain…
## # … with 9,374 more rowsOnce again, we use quanteda to calculate the AFINN score. The program below is actually the same as the one above.
## Warning: 'dfm.character()' is deprecated. Use 'tokens()' first.## Warning: '...' should not be used for tokens() arguments; use 'tokens()' first.So now, we have the information about the device and the AFINN score.
## # A tibble: 9,384 × 3
## afinn android `trump_tweets_target$text`
## <dbl> <lgl> <chr>
## 1 0.5 FALSE "RT @realDonaldTrump: Happy Birthday @DonaldJTrumpJr!\nhttps…
## 2 0.75 FALSE "Happy Birthday @DonaldJTrumpJr!\nhttps://t.co/uRxyCD3hBz"
## 3 -0.0714 TRUE "Happy New Year to all, including to my many enemies and tho…
## 4 0.0952 TRUE "Russians are playing @CNN and @NBCNews for such fools - fun…
## 5 0.118 FALSE "Join @AmerIcan32, founded by Hall of Fame legend @JimBrownN…
## 6 0.214 TRUE "Great move on delay (by V. Putin) - I always knew he was ve…
## 7 0 FALSE "My Administration will follow two simple rules: https://t.c…
## 8 0.333 FALSE "'Economists say Trump delivered hope' https://t.co/SjGBgglI…
## 9 -0.0417 TRUE "not anymore. The beginning of the end was the horrible Iran…
## 10 -0.04 TRUE "We cannot continue to let Israel be treated with such total…
## # … with 9,374 more rowsWe can see the mean AFINN scores of tweets from Android and iPhone.
## # A tibble: 2 × 4
## mean_afinn lower upper phone
## <dbl> <dbl> <dbl> <chr>
## 1 0.127 0.117 0.136 iPhone
## 2 0.101 0.0963 0.106 AndroidTweets from Android are having a slightly lower sentiment score (more negative) than those from iPhone. We can also conduct a test to study the statistical significance of the difference.
##
## Wilcoxon rank sum test with continuity correction
##
## data: afinn by android
## W = 8882012, p-value = 4.213e-07
## alternative hypothesis: true location shift is not equal to 0It is statistically significant. You can see the distributions of AFINN scores of tweets from an Android and an iPhone with the following histogram.
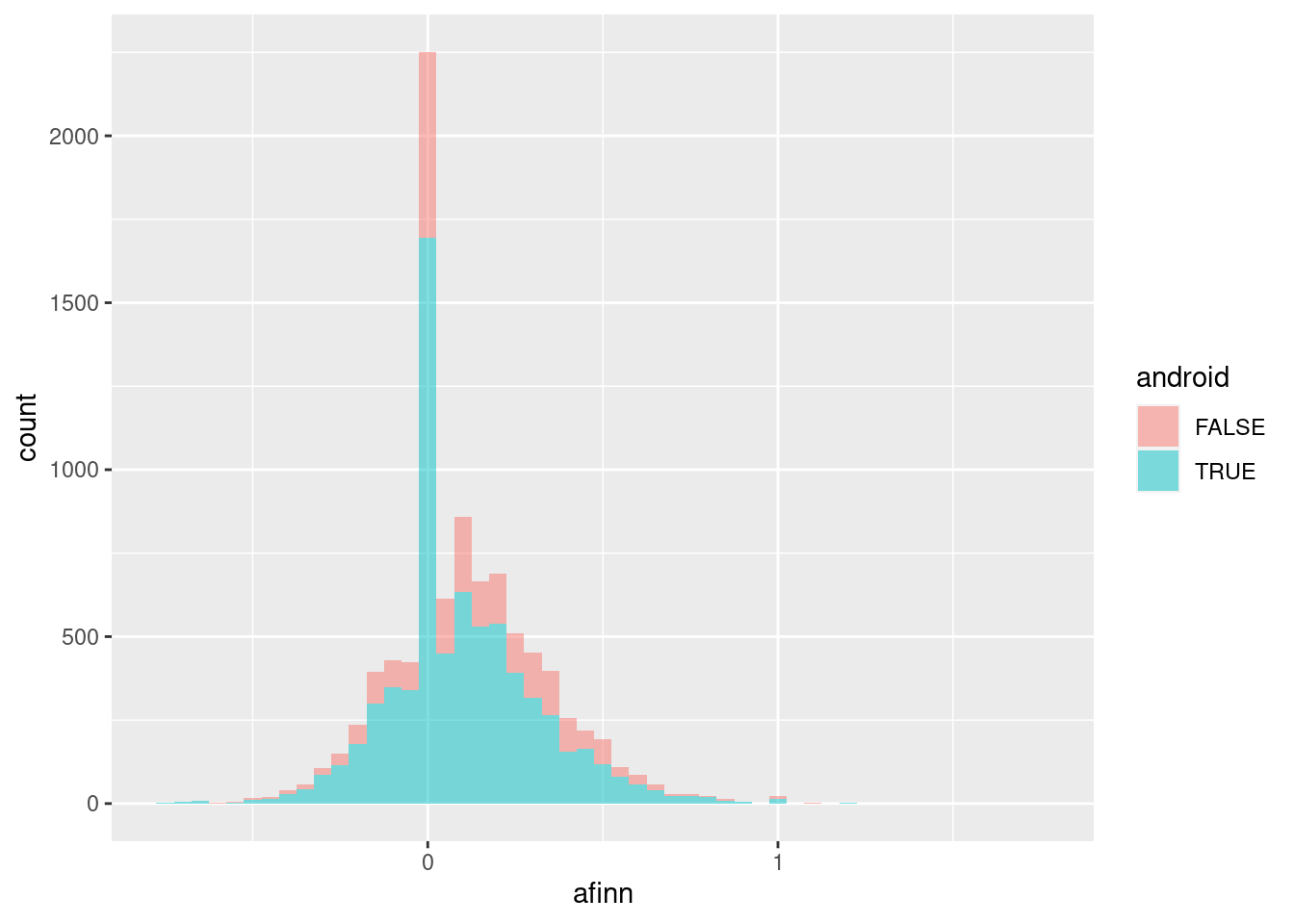
In summary, Trump’s tweets from an Android phone are more negative than those from an iPhone. We have arrived at a very similar conclusion to Robinson’s, although the effect size is much smaller.
The obvious question you may ask is: Why could Robinson get such a large effect size? A more important question: Whom should you trust?
In Chapter 6, we will have a more detailed discussion about the pros and cons of using dictionary-based methods. Regarding the question of “whom should you trust?”, our approach has face validity and criterion validity. For face validity, We have used a dictionary designed for studying social media data (AFINN), whereas David Robinson used NRC dictionaries which are not designed for studying social media data. For criterion validity, we have validated our AFINN scores with some human-categorized tweets. We have evidence that our AFINN scores correlate well with human judgements of sentiment. David Robinson had no such information.
There are some information which is important. Dictionary-based methods are very sensitive to content length. One thing you need to know is that Trump’s tweets from an android are in general longer than tweets from an iPhone. Also, these tweets are in general more negative.
## # A tibble: 2 × 3
## android mean_ntokens mean_afinn
## <lgl> <dbl> <dbl>
## 1 FALSE 14.7 0.127
## 2 TRUE 17.6 0.101We can demonstrate it using a scatterplot.
## `geom_smooth()` using formula 'y ~ x'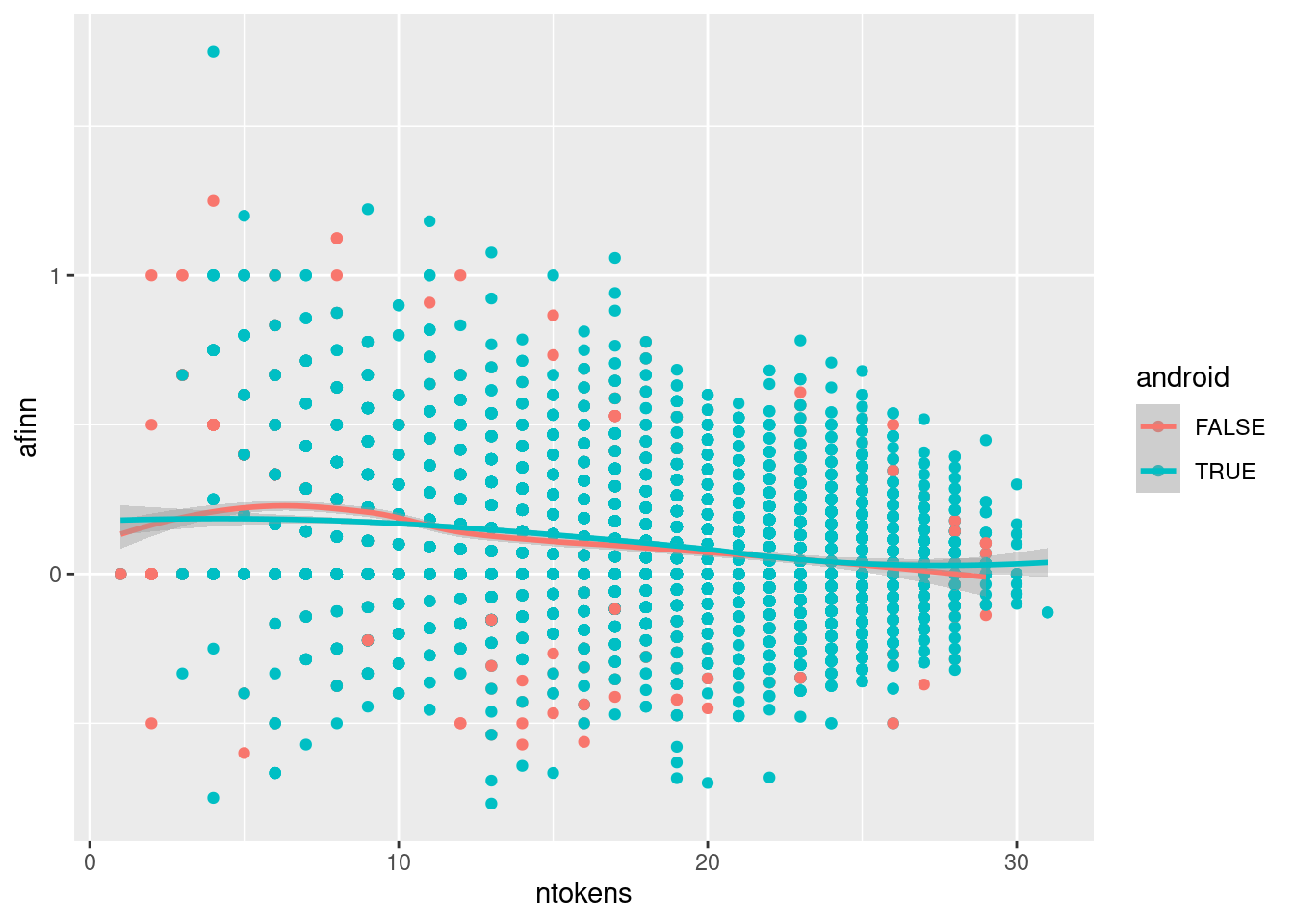
In Chapter 6, I will demonstrate further why we always need to check for the influence of content length. In our AFINN score calculation, we have adjusted for the effect of content length. However, our AFINN score is still correlated with content length with a correlation coefficient of -0.25.
OK, enough. This is not a diss track. Let’s move on and go to the summary of this chapter, shall we?
3.6 Summary
In this chapter, I have used a “whole game” to demonstrate the differences between automated content analysis and other approaches. It can be summarized into a few bullet points:
- Automated content analysis always starts with research questions or hypotheses.
- Automated content analysis is a class of content analysis, therefore, we need to demonstrate the validity and reliability of our measurement.
- Automated content analysis is usually a cost-cutting measure because manual content analysis is very expensive when n is getting larger.
- We can extract semantics from a piece of text using automated methods. But we must bear in mind that these extracted semantics are surrogate —Not always true—. Because of the bullet point 2 above, we need to show that the surrogate measure is a good approximation of human judgement.
- There are many (hidden) problems associated with automated extraction of semantics from a piece of text.
I hope this chapter can motivate you to dig deeper into the world of automated content analysis. In the next chapter, we are going to define (automated) content analysis and establish some best practices.
References
Benoit, Kenneth, Kohei Watanabe, Haiyan Wang, Paul Nulty, Adam Obeng, Stefan Müller, and Akitaka Matsuo. 2018. “Quanteda: An R Package for the Quantitative Analysis of Textual Data.” Journal of Open Source Software 3 (30): 774. https://doi.org/10.21105/joss.00774.
Chan, Chung-hong, and Marius Sältzer. 2020. “Oolong: An R Package for Validating Automated Content Analysis Tools.” Journal of Open Source Software 5 (55): 2461. https://doi.org/10.21105/joss.02461.
Liang, Hai, and Jonathan JH Zhu. 2017. “Big Data, Collection of (Social Media, Harvesting).” The International Encyclopedia of Communication Research Methods, 1–18. https://doi.org/10.1002/9781118901731.iecrm0015.
Munzert, Simon, Christian Rubba, Peter Meißner, and Dominic Nyhuis. 2014. Automated Data Collection with R: A Practical Guide to Web Scraping and Text Mining. John Wiley & Sons.
Nielsen, Finn. 2011. “A New Anew: Evaluation of a Word List for Sentiment Analysis in Microblogs.” arXiv Preprint arXiv:1103.2903.
Perkins, David. 2010. Making Learning Whole: How Seven Principles of Teaching Can Transform Education. John Wiley & Sons.
Upton, Graham, and Ian Cook. 2014. A Dictionary of Statistics 3e. Oxford university press.
Wickham, Hadley. 2011. “The Split-Apply-Combine Strategy for Data Analysis.” Journal of Statistical Software 40 (1): 1–29. https://doi.org/10.18637/jss.v040.i01.
Well, to the author of this book, this chapter is like the first level of the SNES hame ‘Megaman X’. This level demonstrates the mechanic of the game. ↩
The author of this book admits that he is not an expert in communication theories.↩
This code should be replaced with count(), but for the sake of education, let’s bear with me with a combination of group_by and summarise↩
Probably social scientists used the word “code” as a verb earlier than programmers. This is a problem of English. German has two different verbs: kodieren and coden.↩